How to Opt Out of AI Training on Major Platforms
"You have the right to remain silent. Anything you say can and will be used .. for training AI!"
These days every popular online service collects data for training their own AI by default. If you feel uncomfortable in providing your data for AI, ther is a way to opt out! See the list of the popular services and instructions on how to opt out:
You can disable using your data for AI training on this page. Note: If you don't see this option and you are located in the European Union, it means your data is not being used due to your location and because of European Artificial Intelligence Act (AI Act) adopted in 2024.
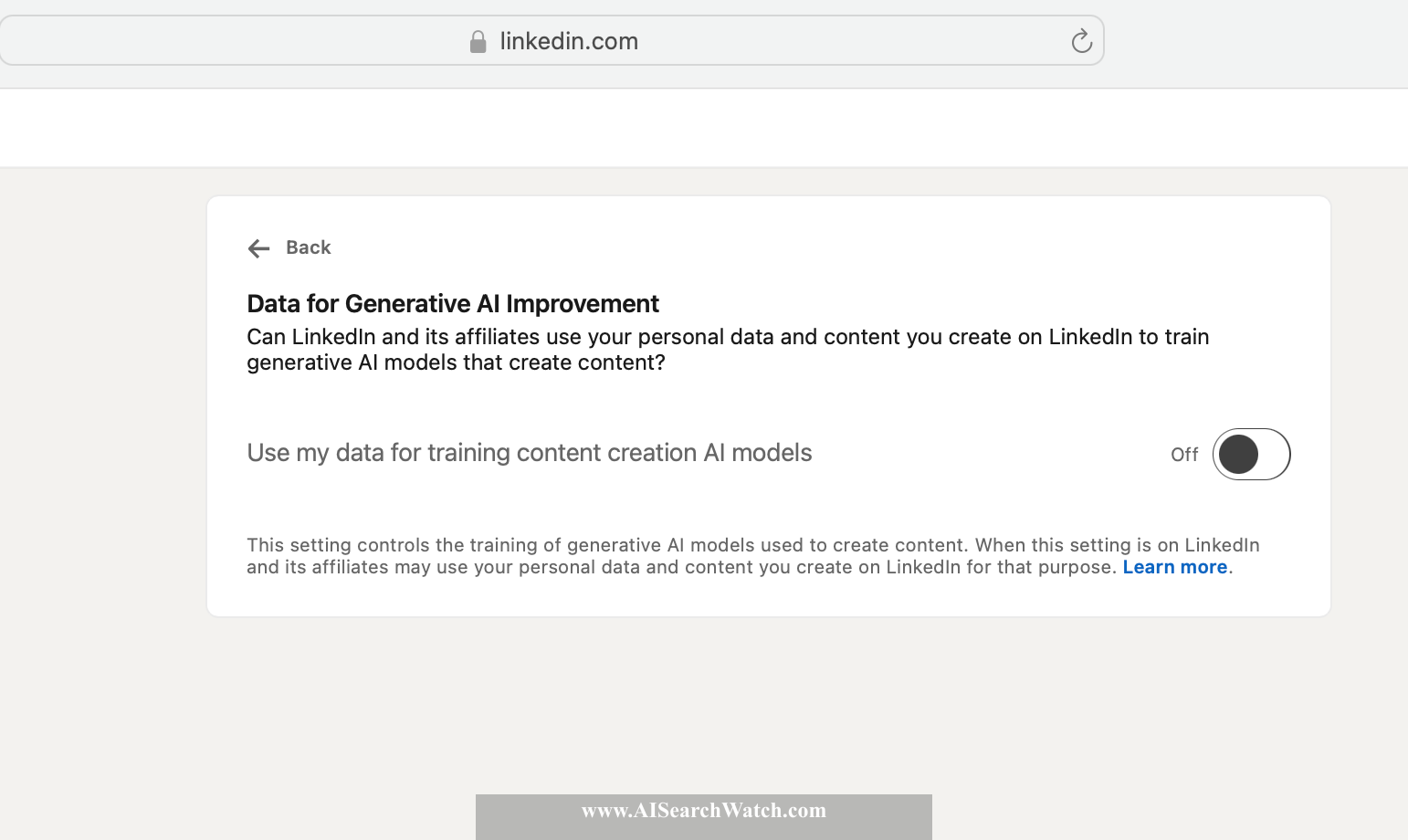
Meta (Facebook and Instagram)
Back to ContentsThere is no off switch but you may send a request through this form.
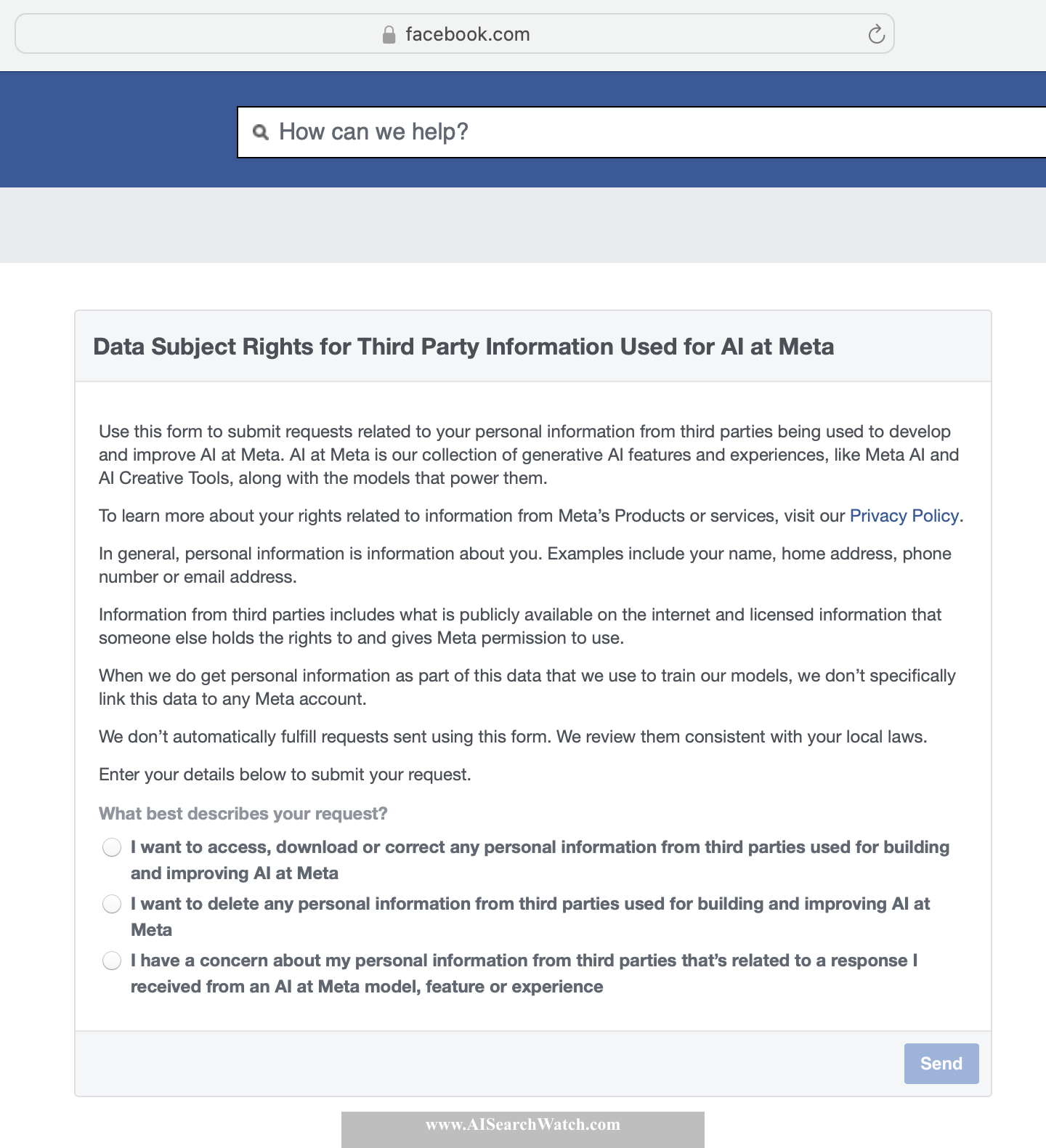
X (aka Twitter)
Back to ContentsYou can disable use of your data for training Grok AI model on this page.
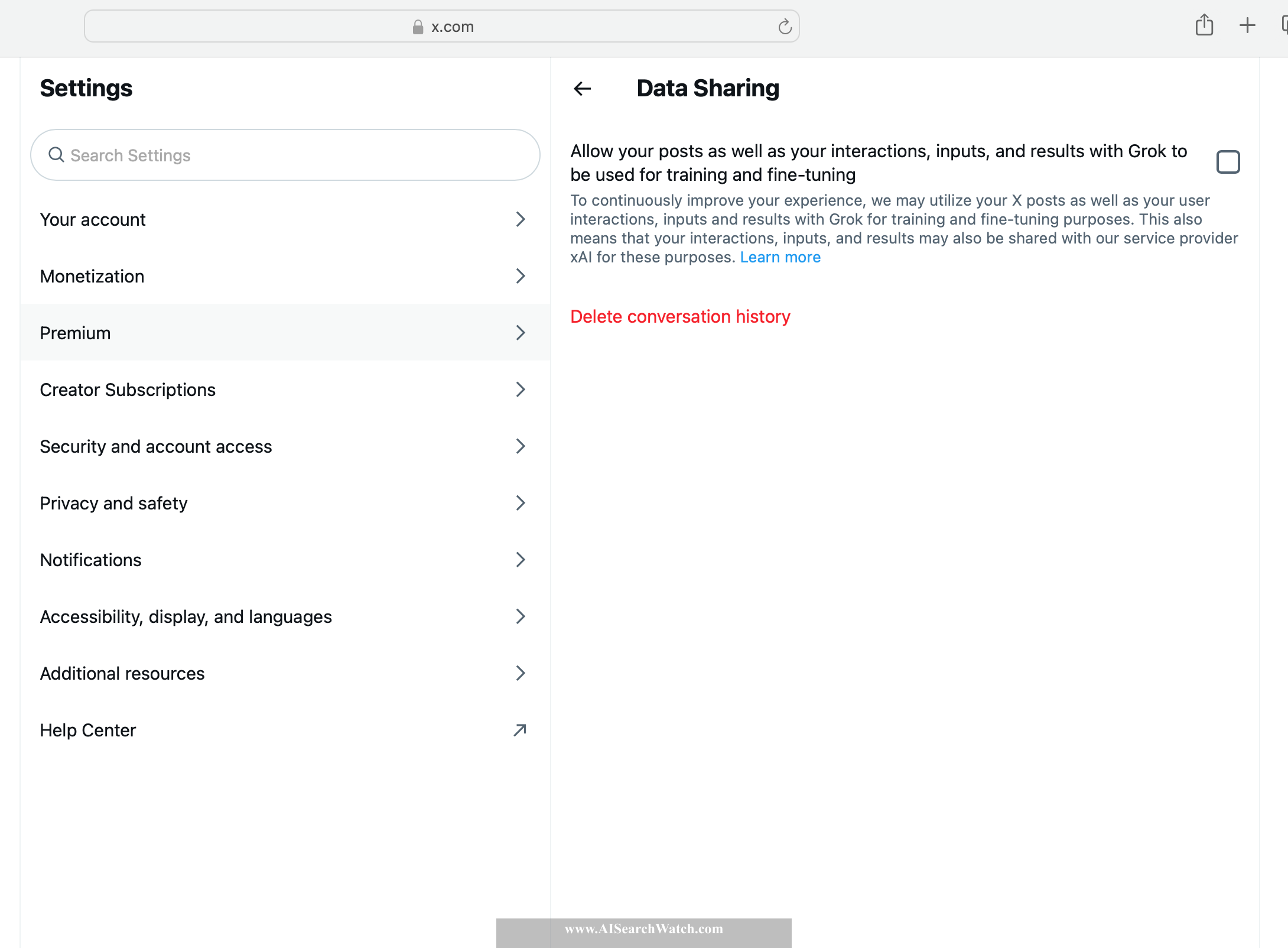
Open AI ChatGPT
Back to ContentsIMPORTANT: If you use the service without logging in, then your inputs and outputs are collected and used for AI training by default.
- Login with your account at https://chatgpt.com, and click on your profile icon (right-top icon).
- Choose settings.
- Then select "Data Controls", then "Improve the model for everyone" and set to "Off"
Anthropic Claude
Back to ContentsIMPORTANT: If you use the service without logging in, then your inputs and outputs are collected and used for AI training by default.
No separate switch to turn off using your data for AI training. Also, Anthropic currently (as of September 2024) says that "Anthropic may not train models on Customer Content from paid Services." if you use their paid product (see their commercial terms).
Also, Anthropic reserves the right to store your input and output from 2 to 7 years in case it was automatically flagged by their trust and safety classifiers as violating Anthropic's Usage Policy. More information here.
If you delete a conversation then Anthropic automatically deletes user prompts and outputs on its backend within 30 days, unless you submit a separate data deletion request. More information here.

Perplexity AI
Back to ContentsIMPORTANT: If you use the service without logging in, then your inputs and outputs are collected and used for AI training by default.
Go to Perplexity AI settings and turn off the "AI Data Retention" switch.
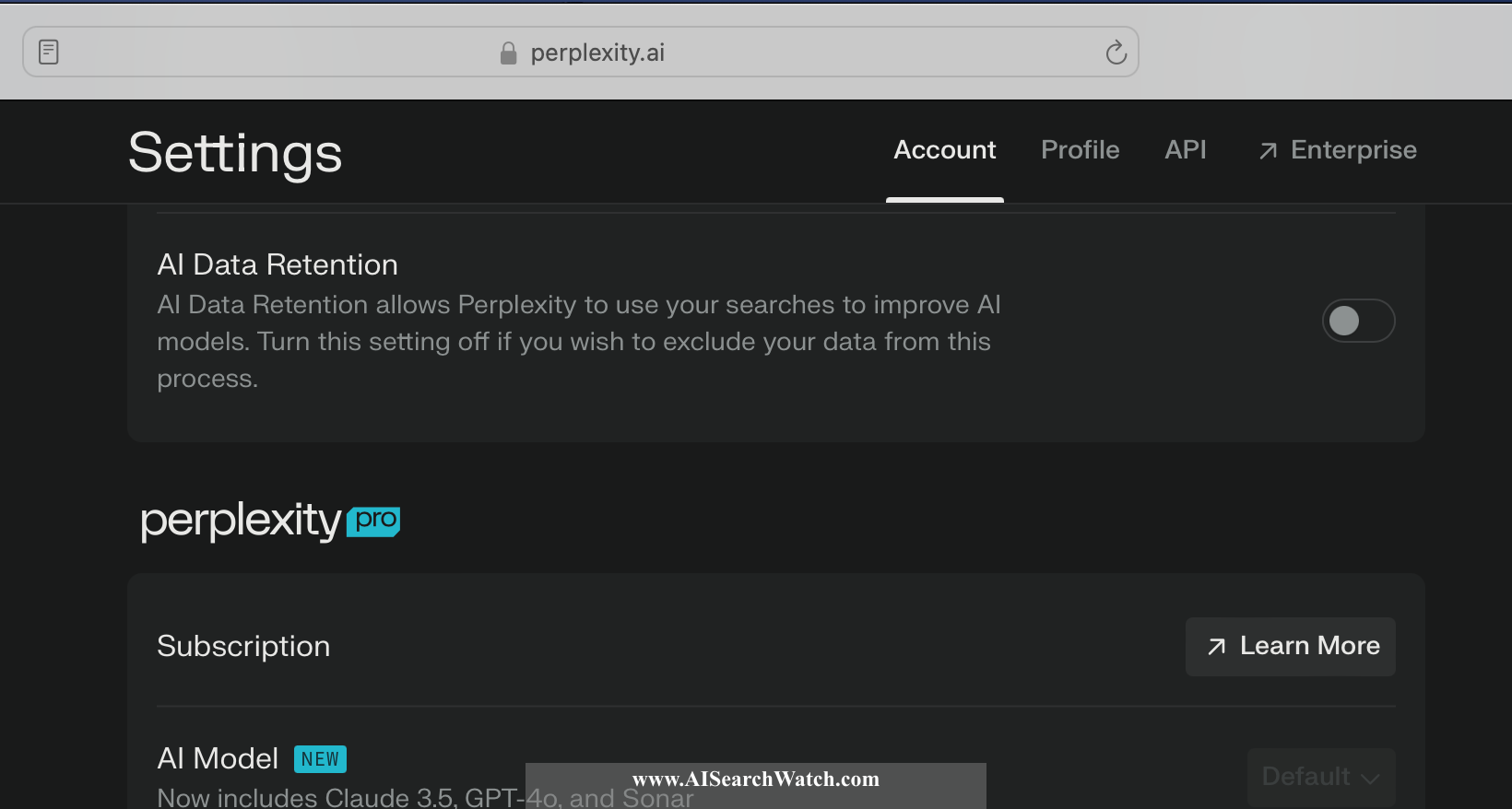
IMPORTANT: If you use the service without logging in, then your inputs and outputs are collected and used for AI training by default.
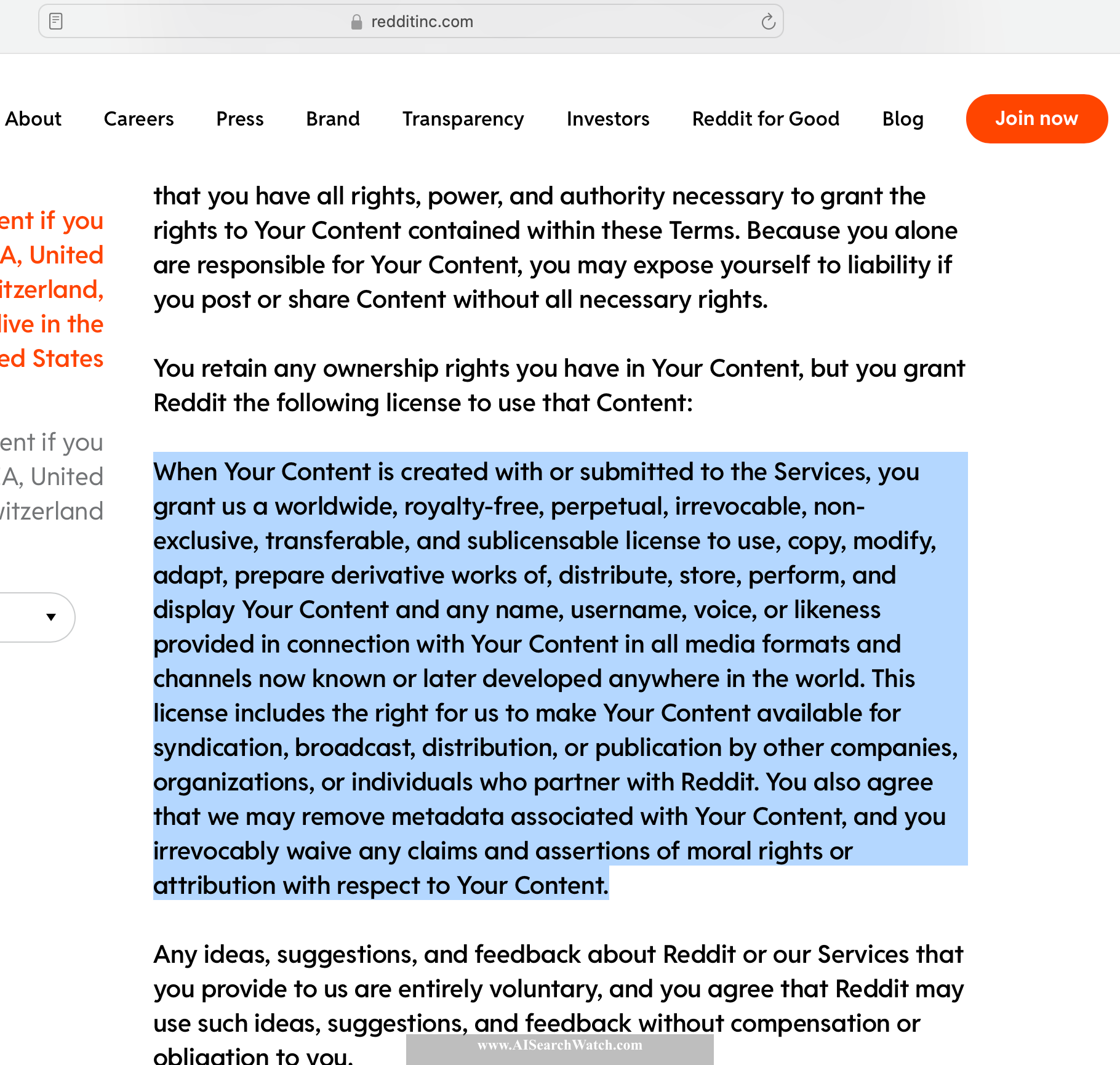
Reddit does not have a separate switch to exclude your data from AI training. According to Reddit's Terms of Use, by using Reddit you provide them with "...worldwide, royalty-free, perpetual, irrevocable, non-exclusive, transferable, and sublicensable license to use, copy, modify, adapt, prepare derivative works of, distribute, store, perform, and display Your Content and any name, username, voice, or likeness provided in connection with Your Content in all media formats and channels now known or later developed anywhere in the world. This license includes the right for us to make Your Content available for syndication, broadcast, distribution, or publication by other companies, organizations, or individuals who partner with Reddit."
Reddit is licensing user data to third parties that may use your data to train AI (source).
However, you may remove your posts and comments if required through this page.
Wordpress.com
Back to ContentsIf you are hosting your website on Wordpress.com then your content is used by Wordpress.com for AI training by default (and also for sharing with 3rd party services).
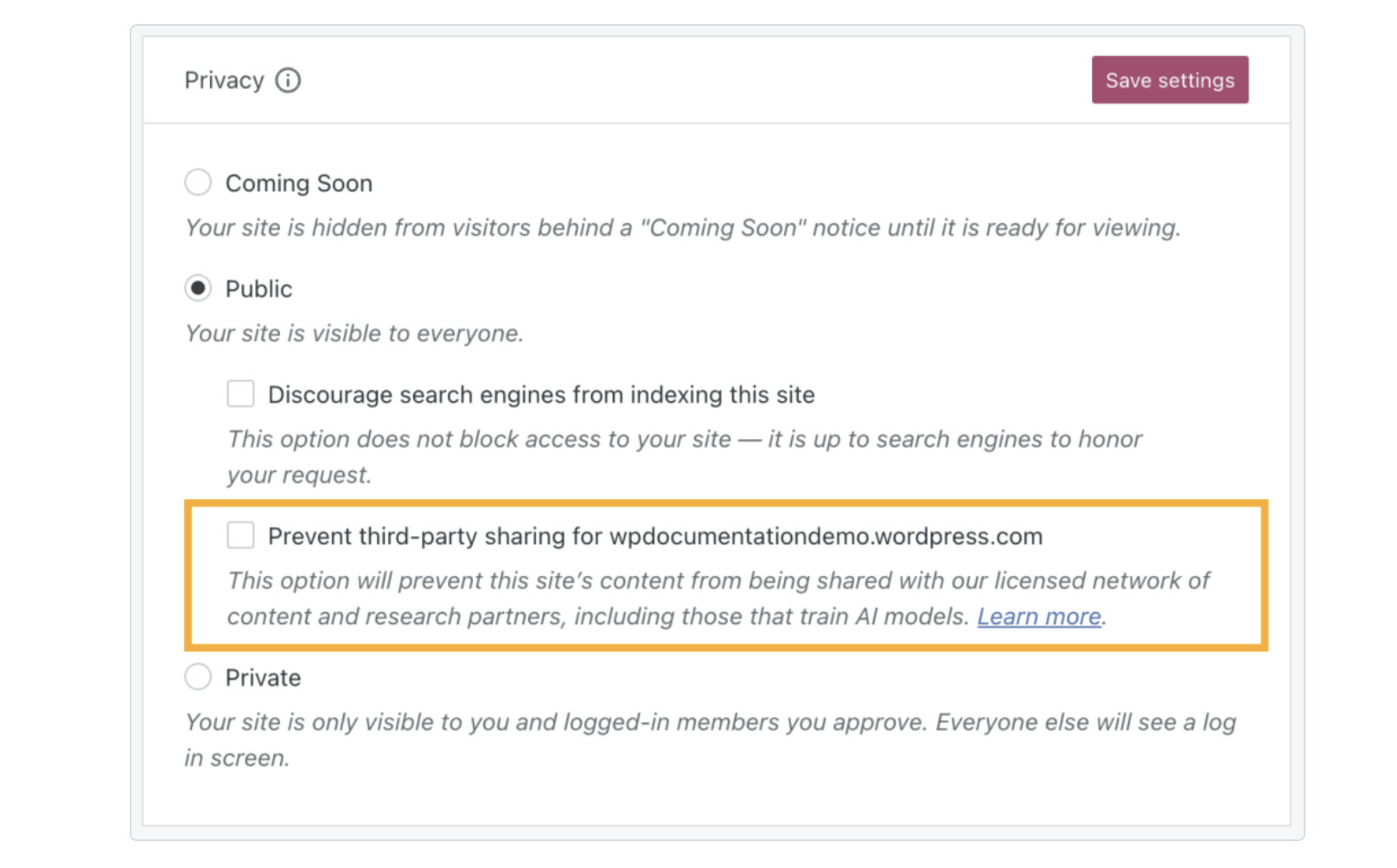
- To turn it off you need to go to the Admin panel (dashboard) of your wordpress.com hosted website (for example,
https://YOURWEBSITE.wordpress.com/wp-admin/). Then go to Navigate toSettings → General(orHosting → Site Settingsif use WP-Admin). - Then scroll down to the Personalization section and enable the Prevent third-party sharing for YOURWEBSITE.wordpress.com option.
- If you run multiple websites on Wordpress.com, you need to enable this option for all of them one by one!
For more details about disabling your content from use for AI training, please visit this page: https://wordpress.com/support/privacy-settings/make-your-website-public/#prevent-third-party-sharing.
GitHub CoPilot
Back to ContentsIMPORTANT: GitHub Copilot uses public repositories with permissive licenses for training its AI models. Here are three ways to prevent GitHub Copilot from using your code for training:
- Do not use GitHub: The most effective way to ensure your code is not used for AI training is to avoid using GitHub altogether.
- Keep repositories private: By keeping your repositories private, you can prevent GitHub Copilot from accessing and using your code for training purposes.
- Use restrictive licenses for public repositories: For public repositories, you can use a restrictive license or even no license to avoid giving explicit permission for your code to be used for AI training. This can help limit the use of your code by GitHub Copilot.
If your organization uses GitHub Copilot, you can exclude certain content from being used by it. For more details, visit this page
GitHub - Your Repositories In Datasets Used By Popular LLMs
Back to ContentsMany of LLMs (Large Language Models) use Stack v2 dataset for training. This dataset is a collection of public source code in 600 programming languages and sized at about 67 terrabytes. It includes source code from GitHub repositories with permissive licenses.
You can prevent your code (from your public Github repositories) from being included into this Stack v2 dataset and therefore exclude it from being used for AI training.
- First, to check if your reposities are included into Stack dataset, please visit this page https://huggingface.co/spaces/bigcode/in-the-stack and enter your github username.
- If your repositories are included, create a new issue at https://github.com/bigcode-project/opt-out-v2/issues/new?&template=opt-out-request.md to request the exclusion of your repositories from future versions of Stack v2 dataset.
If you want to learn more about Stack v2 dataset, please visit https://huggingface.co/datasets/bigcode/the-stack-v2.
Substack
Back to ContentsIMPORTANT: By default, Substack does not block AI bots from using your content for training purposes.
To prevent AI bots from using your Substack content for training, you need to enable the "Block AI training" option. This option is available on the "Settings" page of your Substack account.
Follow these steps to enable the "Block AI training" option:
- Log in to your Substack account and navigate to the "Settings" page.
- Scroll down to the "Block AI training" section.
- Enable the "Block AI training" option by toggling the switch.
Please note that this option just updated public rules for AI bots. But some AI bots have been observed not respecting these public rules (like robots.txt and similar rules defining access). Therefore, if your Substack page is public, some AI bots may still have access to your content despite enabling this option. Because of this, this option does not gurarntee that your content will not be used for AI training.
Add rules for AI bots to your website
Back to ContentsIf you are running a commercial website to promote your business or sell things, or providing a service, you may want to allow your website to be indexed by AI search engines so regular users could easily discover your website via AI when needed.
However, if you are running a website where you don't want your content to be captured by robots.txt file (or you want this content to be exclusively available and known through your website only), then you first need to define robots.txt file that defines rules for web bots.If you don't have robots.txt on your website then web bots (including ones used by AI) will consider they are allowed to read and learn from your website without any restrictions.
Here are some examples of how to use the robots.txt file to control the access of web bots, including AI bots, to your website:
Example 1: Disallow All Bots
User-agent: *
Disallow: /
This rule tells all bots that they are not allowed to access any part of your website.
Example 2: Allow All Bots
User-agent: *
Disallow:
This rule tells all bots that they are allowed to access all parts of your website.
Example 3: Disallow Specific Bots
User-agent: CCBot
Disallow: /
User-agent: anthropic-ai
Disallow: /
This rule tells a specific bot (in this case, "CCBot" which is used for Common Crawl (used by ChatGPT and many others) and "anthropic-ai" which is used for Anthropic) that it is not allowed to access any part of your website.
Example 4: Disallow All Bots from Specific Directories
User-agent: *
Disallow: /private/
Disallow: /tmp/
This rule tells all bots that they are not allowed to access the "/private/" and "/tmp/" directories of your website.
IMPORTANT: this rule is voluntary and some web and AI bots may ignore it and read these directories from to your website despite this rule.
Example 5: Allow Specific Bots
User-agent: Googlebot
Disallow:
User-agent: *
Disallow: /
This rule tells the Googlebot (which is used by Google Search indexing) that it is allowed to access all parts of your website, while all other bots (defined as *) are not allowed to access any part of your website.
By using these examples, you can customize the robots.txt file to control which bots can access your website and which parts of your website they can access.
That's why we've created this free tool that allows you to quickly create a special file (robots.txt) that disallows AI from reading and learning from your website.
IMPORTANT: while robots.txt file is a standard way to define rules for web bots, it is not a perfect solution. This file is more like a voluntary rules. Some AI bots were cought of not respecting these rules and still accessing and capturing content from websites despite the rules defined in robots.txt file. For more protection (if you need it), please consider adding login/password protection to your website.
About The Author

Eugene Mi
Experienced SEO marketer with 15+ years of experience. Worked with Fortune 500 companies and startups.
Continue Reading:
Use AI with Full Privacy - AI Search Watch
Discover how Local Large Language Models (LLMs) allow you to leverage AI technology while maintaining...
Getting Started with LM Studio: Run AI Models Locally
Learn how to download, install, and use LM Studio to run AI models locally on...
What is an AI Search Engine?
Learn about AI search engines—how they utilize artificial intelligence to enhance internet searching by providing...