Where Do LLMs Learn From: Training Data Analysis
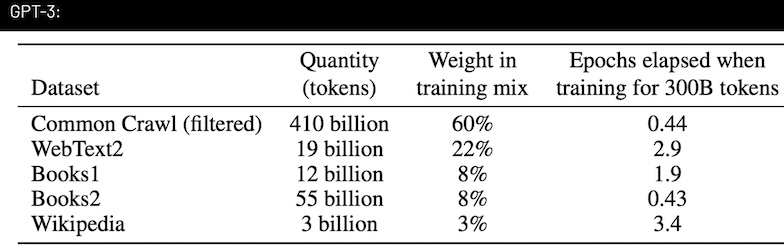
Breakdown of GPT-3's training data sources and their relative proportions
GPT-3: The Foundation of Modern LLMs
Where do these large language models get their knowledge? Let's analyze the groundbreaking datasets used by OpenAI's GPT-3, which marked the beginning of the LLM revolution.
Core Training Sources:
-
1
Common Crawl (60%)
- Largest source:
60%of training data - Monthly-updated snapshot of the Internet
- Contains
400+ billion tokens(≈ 6 million books)
- Largest source:
-
2
WebText2 (22%)
- Based on Reddit-curated content
- 15 years of upvoted links
- High-quality, human-filtered content
-
3
Additional Sources
- Books and Wikipedia articles
- Structured, verified information
Evolution of Training Data

Major Publishers
News CorpAxel SpringerTIMEThe AtlanticThe Wall Street JournalFinancial Times
Online Platforms
Reddit- Community discussionsStack Overflow- Technical knowledgeShutterstock- Visual content
Impact on Search and SEO
Key Implications
- Quality standards are rising as models learn from verified sources
- Technical accuracy is increasingly important due to specialized dataset inclusion
- Community engagement may influence content value in training sets
- Visual content description is becoming more relevant
Future Implications
- Growing importance of authoritative content
- Increased value of technical accuracy
- Rising significance of community engagement
- Enhanced integration of multimedia content
Stay Connected
- Visit AI Search Watch
- Follow on LinkedIn
- Subscribe to newsletter
Part of "The Future of SEO in the Age of AI-Driven Search" series.
References
- Language Models are Few-Shot Learners - OpenAI
- Language Models are Few-Shot Learners - arXiv Paper
- OpenAI Destroyed AI Training Datasets - Business Insider
- OpenWebText2 Background Documentation
- OpenAI News Corp Licensing Deal - AI Business
- OpenAI's Training Data Partnerships - Fast Company
- Overview of OpenAI Partnerships - Originality.ai
